Structuring and rearranging free-hand sketches on large interactive surfaces typically requires making multiple stroke selections. Without well-designed selection tools, this can be both time-consuming and fatiguing. Investigating the concept of automated clustering, we conducted a background study to understand the varying perspectives of how elements in sketches can be grouped. In response to these diverse user expectations, we present cLuster, a flexible, domain-independent clustering approach for free-hand sketches. Our approach is designed to accept an initial user selection, which is then used to calculate a linear combination of pre-trained perspectives in real-time. The remaining elements are then clustered. We demonstrate the utility of our approach in a variety of application scenarios.
Large interactive surfaces, due to their size, can cause strain and fatigue with extended periods of use. Applications should therefore be designed to mitigate these effects. Nevertheless, sketching tools that mimic the use of traditional whiteboards are generally simplistic and lack the means to interpret sketched content. This results in physically demanding and time-consuming selection tasks when users wish to structure or rearrange their sketched content. To address this, many previous works have made attempts to improve selection tools. However, for structuring content, their solutions still necessitate a high degree of effort from the user.
We present cLuster, a domain-independent approach for structuring free-form sketches into sensible groupings to facilitate fast and easy selection and rearrangement. To see what people understand as sensible groupings in sketches, we performed a background study. From more than 300 digital sketches we selected a subset following a modified taxonomy from Walny et al. and asked 14 participants to cluster them. From people’s varied interpretations, we identified nine perspectives, from which we used seven to train our algorithm. Moreover, we learned that one specific sketch can be interpreted in multiple ways.
Clustering
A lot of research in the field of symbol segmentation within well structured domains has exploited the knowledge of the domain to perform segmentation by classification. However, when aiming to stay domain-independent, such an approach cannot be used. Therefore, we use a data mining method called cluster analysis. This divides elements (in our case, strokes) into disjoint sets, where strokes within a cluster share similar characteristics. Recently, Delaye and Lee presented Single-Linkage Agglomerative Clustering (SLAC), a machine learning approach that successfully segmented sketches in several domains. They achieved promising results with segmenting benchmark datasets in domains such as flowcharts, mathematical expressions, loosely defined text blocks, and figures in free-hand sketches. However, they modified their weights, thresholds, and even feature sets to suit each domain. Learning a new set of parameters requires a lot of data (at least ten annotated sketches) and takes a considerable amount of time (from minutes to hours depending on the complexity and the amount of data). Thus, it cannot be done in real-time for each individual input.
Therefore, instead of aiming to learn the SLAC parameters for a specific domain, we used the perspectives found in our background study to define characteristics for the objects of our interest, to annotate training data, and to train our system. This requires an additional layer to be built on top of the clustering method, which combines several sets of weights (from each perspective) learned from different annotated data to make the clustering tool suitable for an individual sketch viewed under a particular perspective. Based on this clustering system, we can build tools that provide a quick adaptation according to the user’s intentions.
Cluster Creation and Refinement
The expectations of how a sketch should be clustered can be quite diverse. Furthermore, even if expectations were to match between users, one cannot expect even a very well-trained algorithm to be consistently accurate. For this reason, we take advantage of the parameters that allow us to configure the granularity and the type of clustering. To achieve the best performance, we implemented a two-step approach, where users can firstly influence the process of clustering by selecting an initial cluster and then change the proposed clusters manually if required.
Selection of the initial cluster
While the distance threshold directly affecting a general cluster size is easy to understand, the coefficients that describe the influence of the different perspectives are hard to comprehend for users. Therefore, we provide the user with the possibility to make an initial selection indicating one cluster (see Figure \ref{fig:initialSelection}). If the clustering is invoked afterwards, our implementation does not only aim to find the required threshold that would create desired clusters but also finds adequate coefficients of the linear combination providing the right way of clustering.

Manual cluster refinement
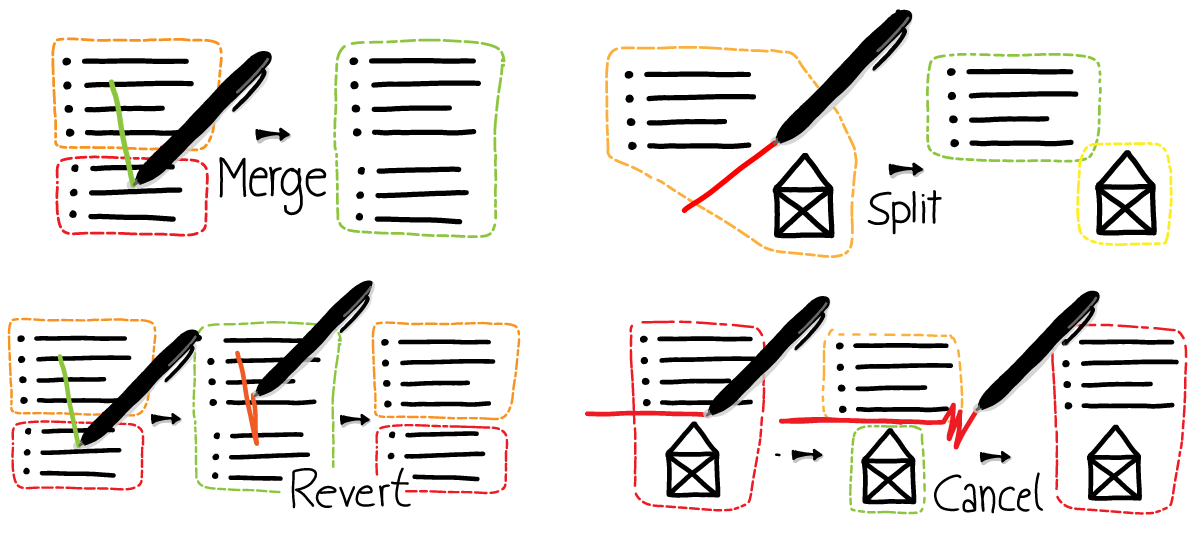
Especially when expectations are ambiguous the clustering algorithms might produce a result that needs slight adaptions. Therefore, we implemented a very easy way to re-group wrong clusters. First of all, users can adapt the system threshold with a simple slider to manipulate the cluster granularity. Figure \ref{fig:union-split} shows that clusters can additionally be split by cutting them with a simple stroke gesture. By drawing a line gesture that intersects two or more clusters, multiple clusters can be merged into one larger cluster. All changes that will happen are shown in a real-time preview manner; this provides the user with the ability to undo a split or merge action by tracing back along the gesture-stroke. Moreover, it is possible to cancel an entire adaption by performing a zig-zag gesture.
Applications
We tested cLuster in several application scenarios that show the utility and the performance of our algorithm in practice.
Advanced Crossing Selection
Besides clustering an entire page with an initial cluster selection as a template, cLuster can also be used to improve the performance of crossing-based selection tools by suggesting possible selections. While crossing a stroke, the system invokes a clustering process and suggests a selection to the user. The predicted selection is then visualized as a surrounding hull. A small icon that follows the users’ pen path can be used to trigger the suggested selection.

Advanced Tapping Selection
While tapping is well suited for single targets, it is cumbersome for large groups. Nowadays, many applications (e.g. text editors) provide the feature that enables users to quickly select a word by performing a double-click, while three clicks in a row selects the entire paragraph. With cLuster, we can achieve similar results in a sketching scenario. A single tap selects one cluster, while a second tap adds the closest cluster to the selection.
After merging two clusters this way, the resulting cluster is used to recalibrate the clustering algorithm. By performing a directional flick gesture, the user can also choose the direction in which the next potential cluster should be found. After merging multiple clusters into one, this selection can be further used.

Advanced Rearrangement
Extensive re-arrangement is a domain where our approach really shines. Clustering the entire page at once eliminates the need to repetitively select strokes when translating groups. All clusters are at hand and can be directly moved or altered. This reduces the effort needed for structuring and rearrangement tasks immensely. However, in many cases users want to move clusters to a position that is already occupied by existing content.
Knowing the placement of all the clusters, they can be moved out of the way to make space automatically. Initially, we used a coalition based approach, however, we soon realized that the behavior was not ideal in many cases. Therefore, we investigated several options of how identified clusters could make space. Of course, each strategy has its pros and cons depending on the type of sketches being manipulated. In the following, we present two possible strategies:
The Spring Strategy simulates a spring’s behaviour. The general rule is that clusters try to remain as close as possible to their original position. This is a very standard approach that can be used for a wide variety of applications. Working with well organized sketches, such as lists or storyboards, the Bubble Strategy is very effective. If a cluster is moved through a list, the other clusters swap their positions with the current selection being moved. This creates a bubble effect that enables easy exchange of clusters without changing the overall list and without needing to rearrange a large number of list items when an entry is relocated within the list.

Real World Use
Within the project IdeaGarden we developed a tablet sketching application based on the cLuster – algorithm. In their workflow designers (e.g. at EOOS, LEGO) often use tracing paper to move individual segments around and to explore different arrangements. To create different layers the designer has to actively sketch the components on different sheets of tracing paper, which interrupts the sketching experience. We considered cLuster to be a possibility to automate this segmentation process. This way, the designer can focus on the sketch without being interrupted as the application allows for sketching without caring about layers or grouping. At any time the sketch can be clustered to arrange individual segments of the sketch. A trained algorithm in the background tries to find suitable clusters. The designer has an influence on the granularity and moreover can manually split or merge clusters if the algorithm is incapable of producing the desired result. Sketches can then be easily filed by directly exporting them to Archipelago 2.0.
Conclusion
cLuster is an efficient way of clustering multiple elements in a non-domain specific sketch. It features an approach that does not just focus on a single way of clustering, but can be adapted to cluster sketches in multiple ways (perspectives) based on an initial user selection. We presented several application scenarios that show the performance and the versatility of our clustering approach. The use-cases show that cLuster can provide an improvement to the sketching experience by providing high-level and responsive interaction without understanding the actual meaning of the sketch, which also makes our approach applicable even when the domain is not specified.